2023年12月7日,谷歌推出自身首个多模态大模型Gemini 1.0,其中高性能版本Gemini Ultra可对标GPT-4。并在10天之内,谷歌Gemini模型Pro版迭代出了1.5版本。
随后第二年初的2月,谷歌又推出新型开源模型系列“Gemma”:该开源模型基于Gemini研究和技术开发,与Gemini相比,Gemma展示了更高的效率和轻量化设计,同时免费提供全套模型权重,并明确允许商业使用。
在如此背景下,随着谷歌大模型不断加速迭代,对其软件层面优化,算力能力的支撑提出更高的要求。而算力的提升一方面来自于底层的芯片性能,另一方面则来自计算集群效率。
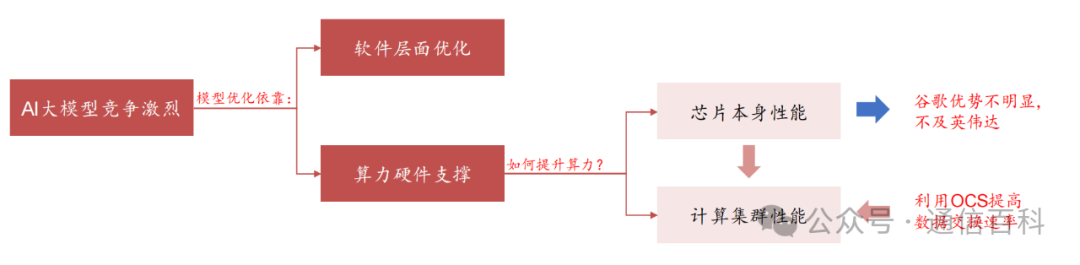
因此,为了高效地将多个计算芯片连接起来,谷歌在通用解决方案基础上,创造性地引入OCS光交换机(Palomar)。那么为何要发展OCS光交换机?
Gemini快速迭代,亟需算力支撑
可以看得出,谷歌大模型的迭代动作一直在加快:
- 2023年初推出聊天机器人Bard:2023年2月6日,谷歌宣布将推出一款聊天机器人Bard,2023年3月21日,谷歌向公众开放Bard 的访问权限。
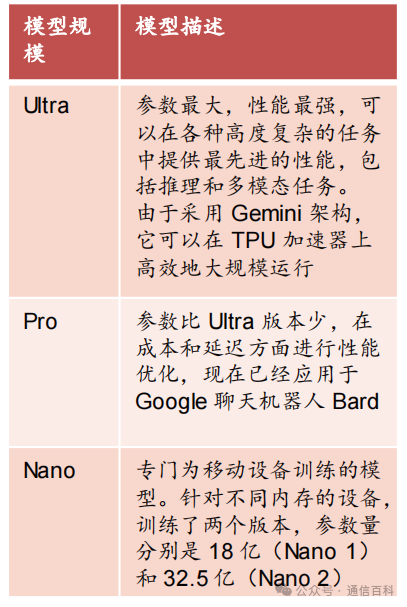
- 2023年12月推出首个多模态大模型Gemini 1.0:模型共分为Ultra、Pro、Nano三个版本。
表:Gemini 1.0三版本对比
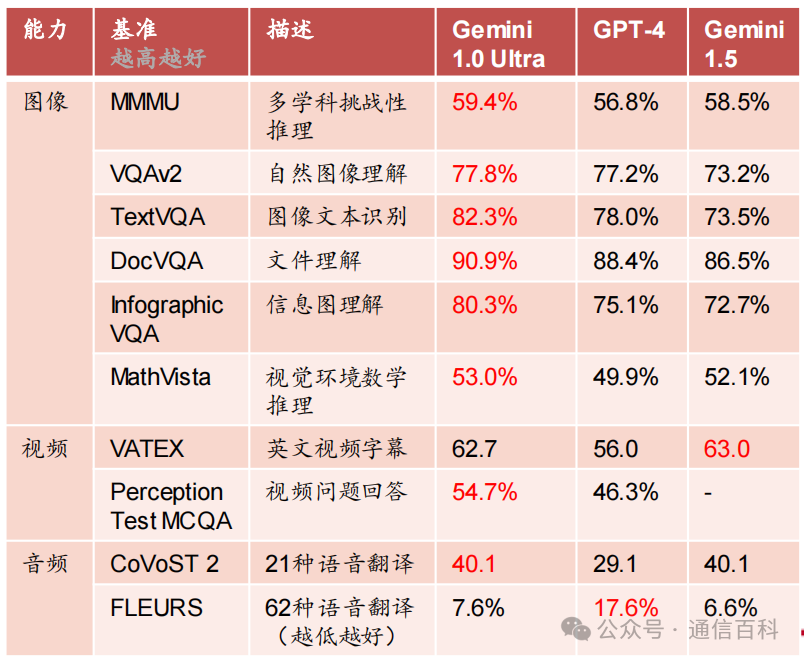
同时将聊天机器人Bard背后的模型从PaLM2换成了Gemini Pro。其中高性能版本Gemini Ultra可对标GPT-4,Gemini Ultra 在大型语言模型(LLM) 研发中使用的32 个广泛使用的学术基准中,有30个的性能超过了当前最先进的结果。
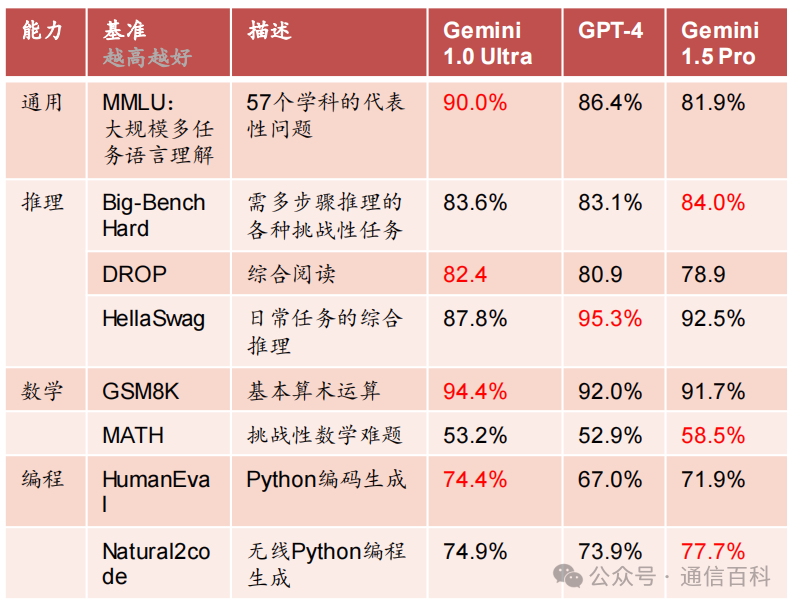
- 2024年2月16日,Gemini 1.0 Pro迭代至1.5:在文本、代码、图像、音频和视频评估达到了与Gemini 1.0 Ultra相当的质量,但减少了计算资源。
- 2024年2月22日,谷歌推出新型开源模型系列“Gemma”。
谷歌自研TPU单芯片性能不足
2015年谷歌首次发布了第一代TPU,正式涉足定制ASIC芯片,2017年发布第二代TPU v2,2018年发布第三代TPU v3,第四代TPU v4于2021年5月正式推出,此次迭代间隔三年,并于2023 年8月推出第五代TPU v5e,以及2023年12月6日最新发布TPU v5p。
表:谷歌历代TPU迭代情况
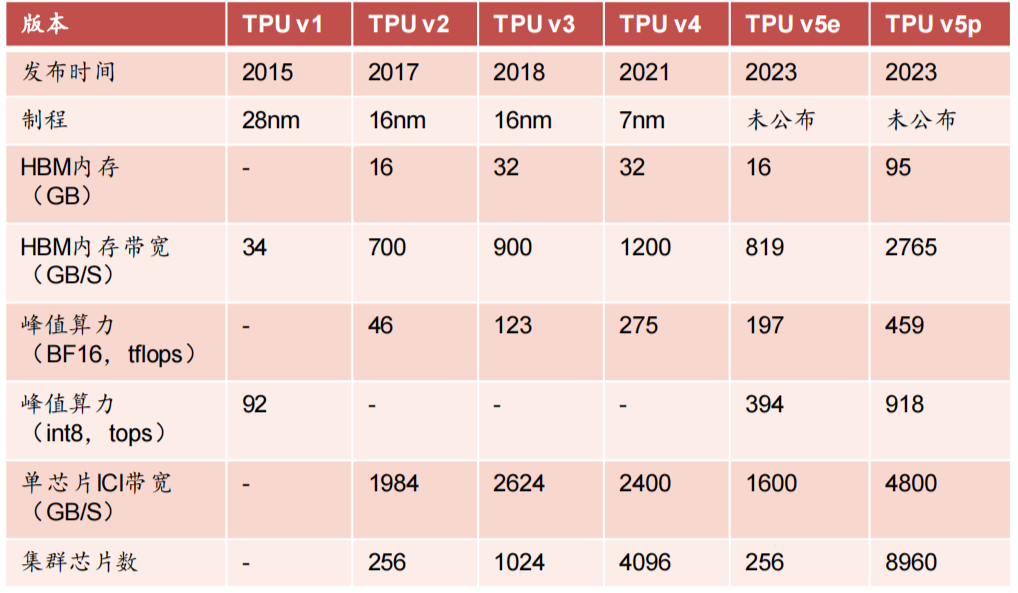
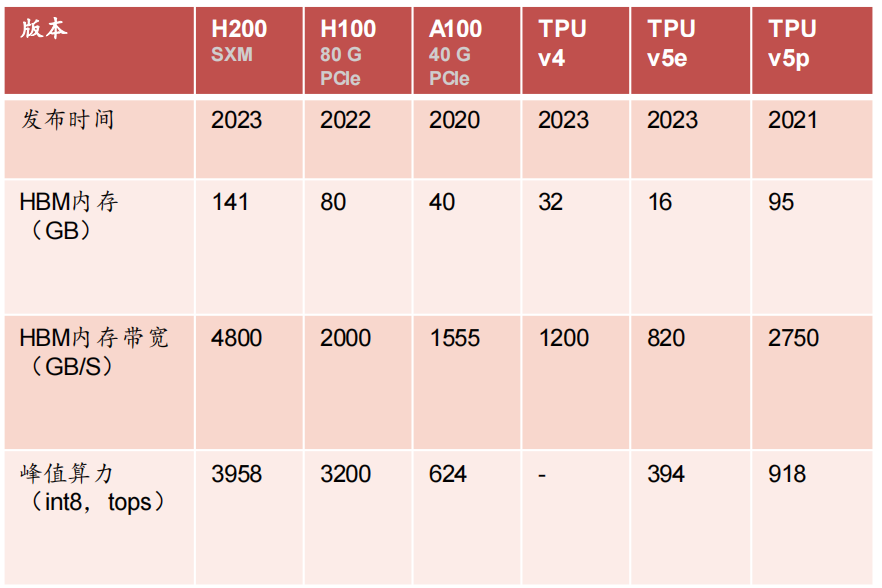
单芯片性能不足,提高计算集群效率(POD)是同英伟达竞争的关键:谷歌训练 Gemini Ultra所使用芯片为TPU v4、TPU v5e,性能无法与英伟达H100相比,TPU v5e峰值算力只有英伟达三年前发布的A100 的六成,最新版本TPU v5p峰值算力不到H100的三成,且英伟达将于2024年推出更高性能的B100产品。
表:谷歌近两代TPU与英伟达近两代产品性能对比
电交换机相比光交换机延迟和功耗较高
传统三层架构:包括接入层、汇聚层和核心层,对应位置均采用电交换机,一台下层交换机会通过两条链路与两台上层交换机互连,实际承载流量的只有一条,其它上行链路,只用于备份,一定程度上造成了带宽的浪费,因此传统网络架构有网络带宽阻塞,上层带宽小于下层带宽和。
◼ 叶脊拓扑结构
相比于传统网络的三层架构,叶脊网络进行了扁平化,变成了两层架构,叶交换机相当于传统三层架构中的接入交换机,脊交换机,相当于核心交换机。
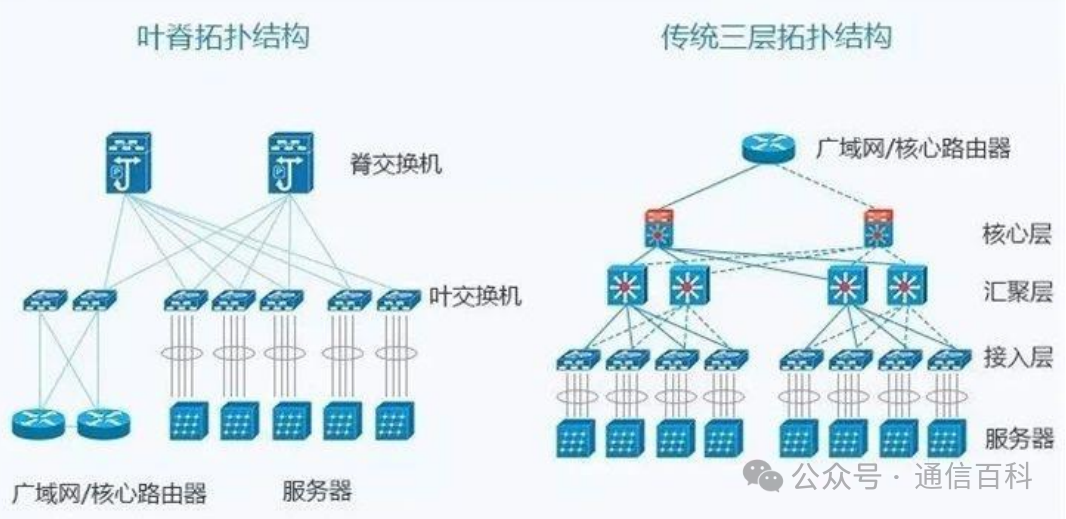
图:传统三层网络架构和叶脊架构对比◼ 胖树架构和英伟达Infiniband架构
传统三层架构存在网络带宽阻塞,在叶脊架构中,视各家具体方案不同,汇聚层或核心层也存在网络带宽阻塞,胖树架构下,自下而上不存在网络带宽阻塞,英伟达infiniband架构采用两层的胖树架构,即叶脊和胖树的结合。
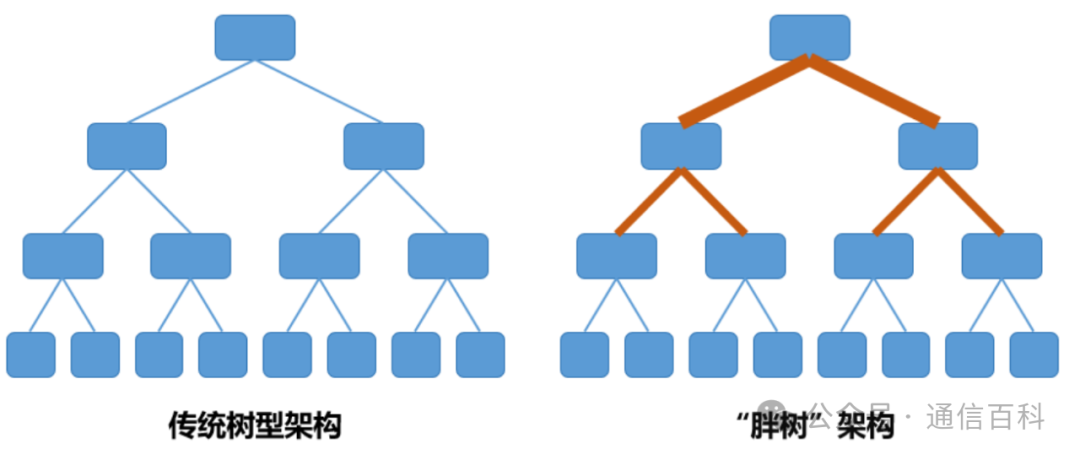
图:传统树形有阻塞三层架构和胖树架构
以上网络架构中,各层交换机均采用电交换机,与光交换机相比存在一些不足:首先耗电量较大,同时因为需要对数据包进行编解码导致延迟较高,另外在摩尔定律下,电交换机相关芯片迭代速率较快,电交换机2-3年迭代一版,频繁迭代下资本支出较大。
TPU v4时期首次引入Palomar OCS提升计算集群性能
谷歌从TPU v2版本开始构建超级计算机集群:谷歌在2017年发布TPU v2的同时,宣布计划研发可扩展云端超级计算机TPU Pods,通过新的计算机网络将64块Cloud TPU相结合。
◼ TPU v3集群(Pod):2018年与TPU v3芯片一同推出,每个Pod最多拥有1024个芯片;
◼ TPU v4集群首次引入OCS:首次引入Palomar OCS(Optical Circuit Switches,光交换机),一个集群总共有4096个TPU,是TPU v3的4倍;
◼ TPU v5p集群:每集群TPU数量达到8960个,每集群可用 FLOP总数是TPU v4的4 倍,每秒浮点运算数(FLOPS)比TPU v4 提高一倍,每Pod芯片数量增加一倍,可以提高训练速度的相对性能;TPU v5p集群同样使用了Palomar光交换机。
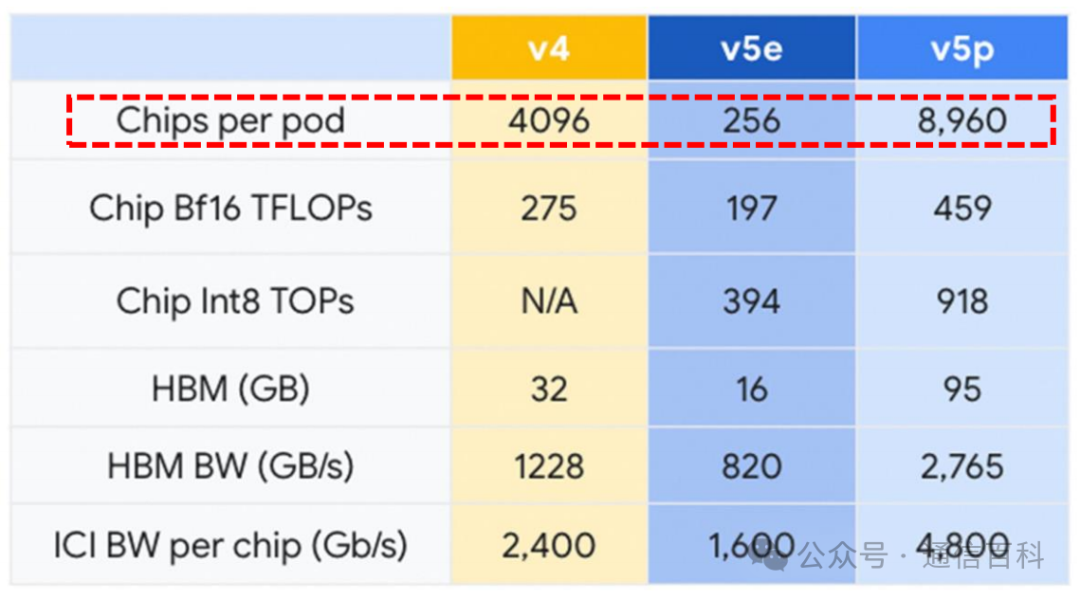
图:谷歌TPU v5p参数及v5p集群芯片数量
短时间内,谷歌在单颗芯片性能上超过英伟达难度较大,通过其擅长的软硬件集成,提高计算集群效率,在支撑自身大模型训练的基础上,可以通过出售算力资源获取收入,Salesforce 和 Lightrick等客户已经在使用Google Cloud 的 TPU v5p 超级计算机来训练大模型。
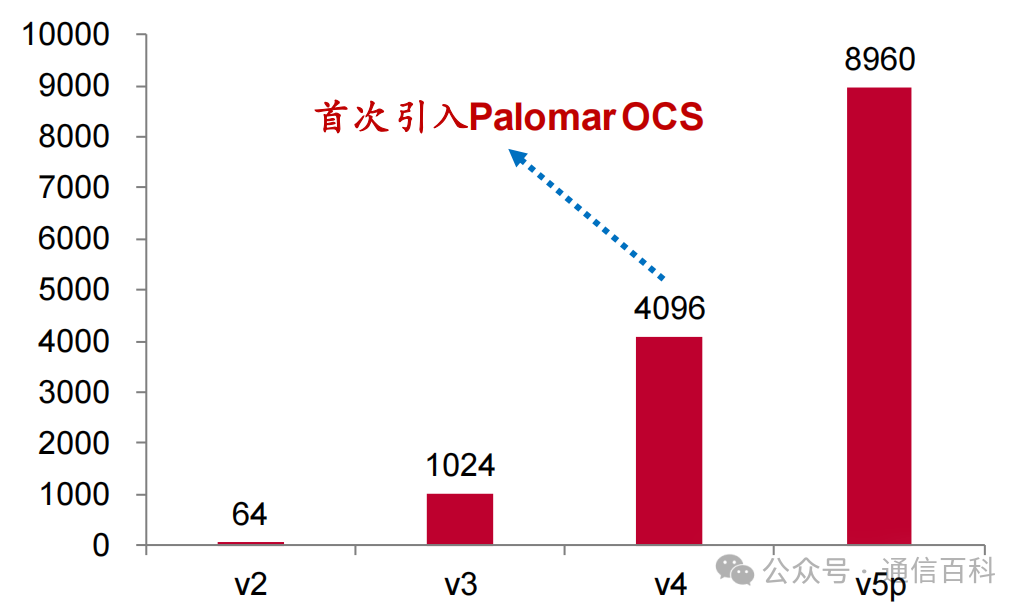
图:谷歌历代TPU集群集成的芯片数量
光交换机降低计算集群功耗、延迟和生命周期成本
早期Jupiter采用“Clos”拓扑:也称为脊叶配置:spine and leaf configuration,机架装有【CPU、GPU、FPGA、存储和/或ASIC 】,然后该机架连接到叶(leaf,汇聚层)或架顶交换机,然后通过各种聚合层连接到主干(spine)。
Clos拓扑下电交换机的资本开支和功耗较大:Clos拓扑中,主干层使用电交换机 (EPS:Electronic Packet Switch),通常由 Broadcom、Cisco、Marvell 等提供,EPS 耗电量大,此外,每 2 到 3 年网络速度翻一番,需升级现有spine层EPS,每一代更新都会带来巨大的资本支出。
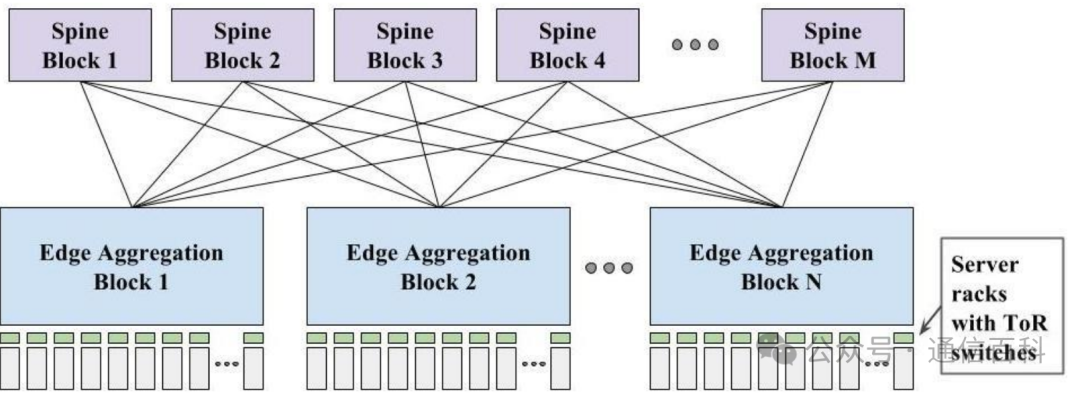
图:早期谷歌Jupiter架构采用Clos拓扑
2022年谷歌引入光交换机替代主干层电交换机降低功耗、延迟和资本开支:引入光交换机取代Spine层传统电交换机,主干层功耗显著下降,同时由于不必解码数据包导致延迟显著降低,且主干层交换设备无须再进行设备代际更新,使用寿命增加,节约全生命周期资本开支;
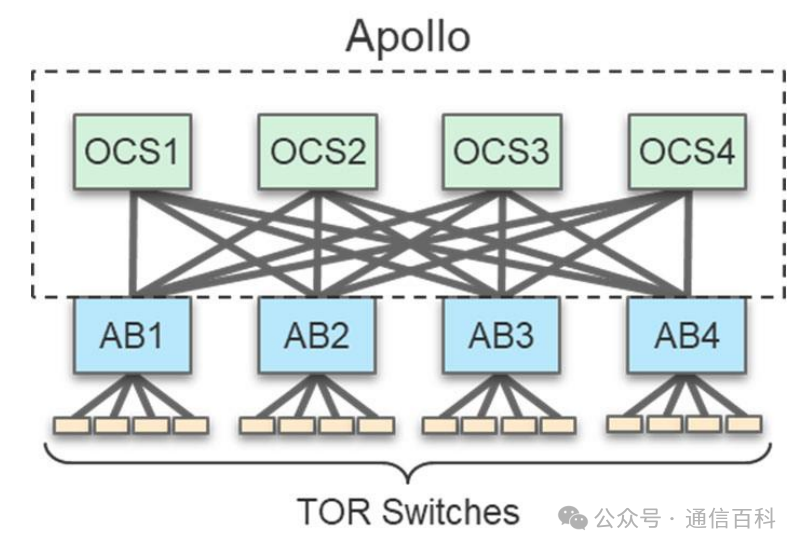
图:引入光交换机取代主干层的电交换机
当然,引入光交换机也存在一些缺点:
- 尽管全生命周期成本下降,但前期资本开支较大;
- 信号插入损耗:光要多次反射折射才能到达接收端,存在信号功率损失;
- 重新配置时间:光交换机的光路是提前设置好的,如果要与不同的端口通信,光开关必须重新配置这些镜像。
本文内容源引于中泰证券的研究报告”AI系列:光是通信的必由之路,OCS已成功应用“