特斯拉没有采用传统的 TCP 协议,而是为其 Dojo 超级计算机开发了一种新的有损以太网传输协议:Tesla Transport Protocol over Ethernet (TTPoE) 。
此协议专为 AI 超级计算机设计,以实现 Exa 级网络架构的数据传输。
与传统的 TCP/IP 协议相比,TTPoE 在硬件层面执行,以解决 AI 互连的延迟问题,它通过简化的软件和硬件设计,实现了更低的延迟和更高的带宽。

原因是:特斯拉认为 TCP/IP 协议速度过慢,而使用 PFC(优先级流控制)的 RDMA (远程直接内存访问)虽然能实现无损网络,但会对网络性能造成影响。

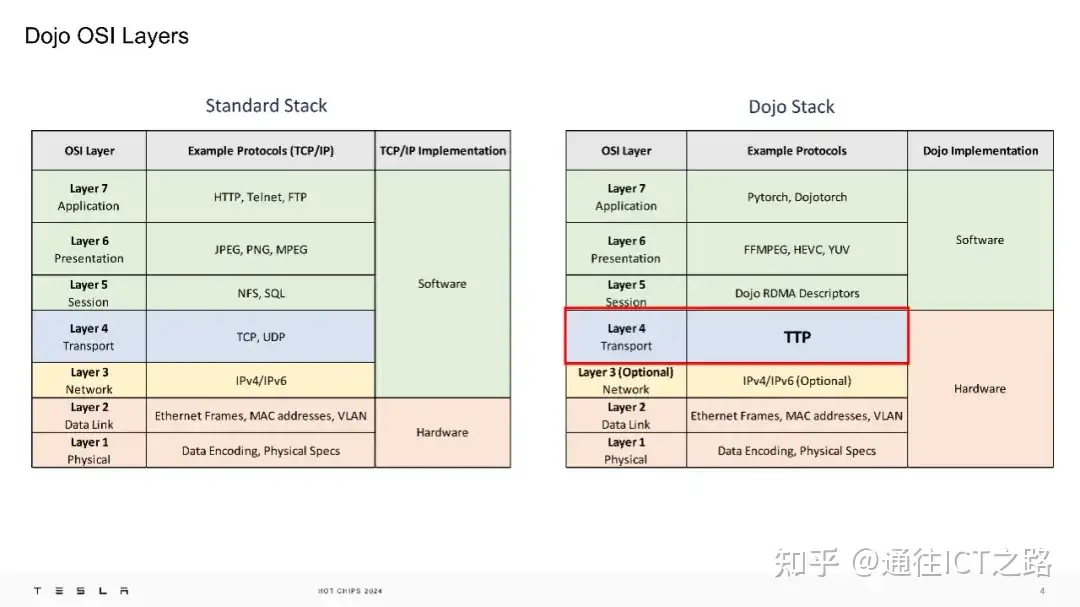
在下面的介绍中,指出 TTPoE 是一个在硬件层面执行的点对点传输层协议,其优势在于特斯拉无需使用特殊的交换机,因为它主要利用的是第二层(数据链路层)的传输。

也就是说,在 Dojo 的 OSI 模型中,特斯拉用 TTPoE 取代了传统的传输层。
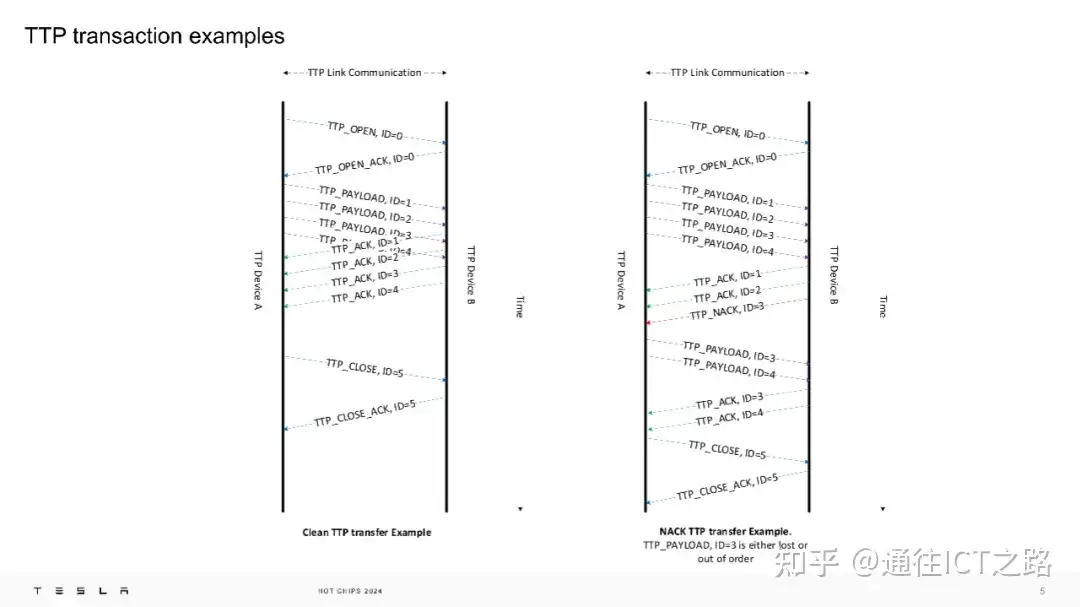
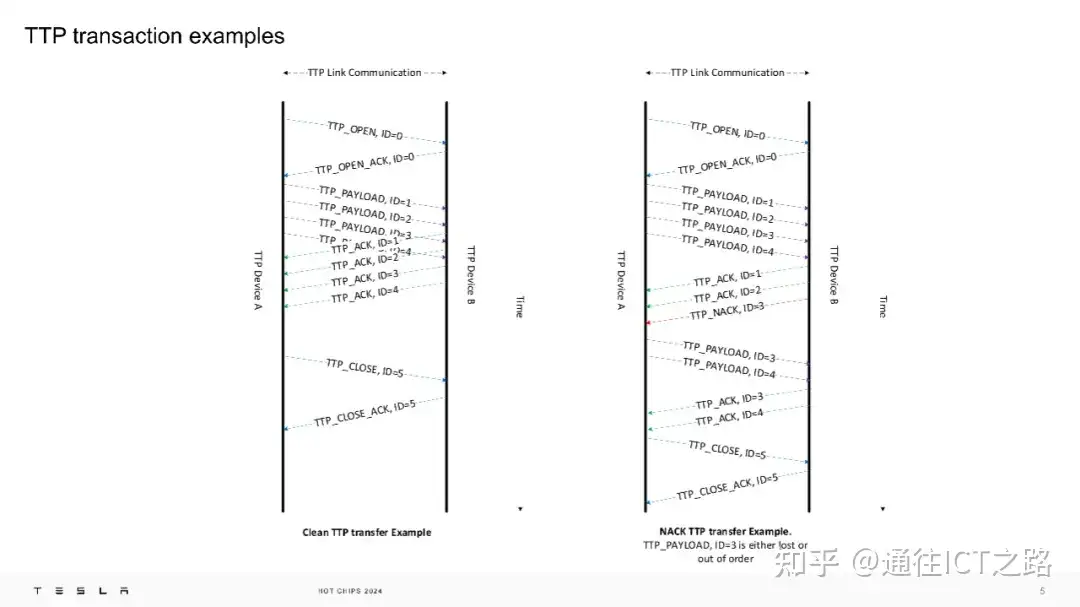
通过 TTP 链路,我们可以看到 TTP 协议的转换示例。
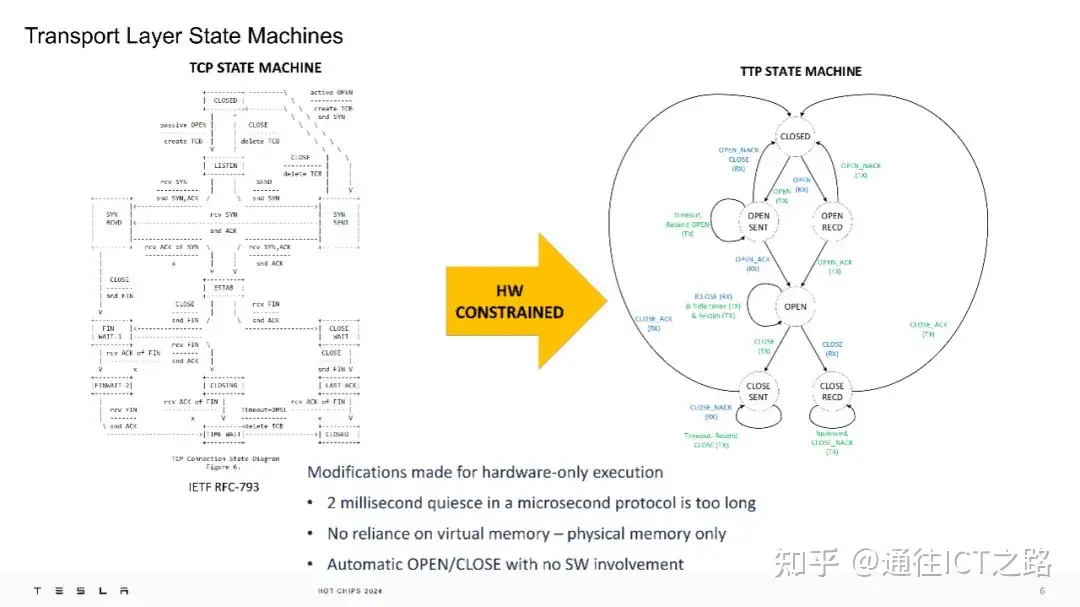
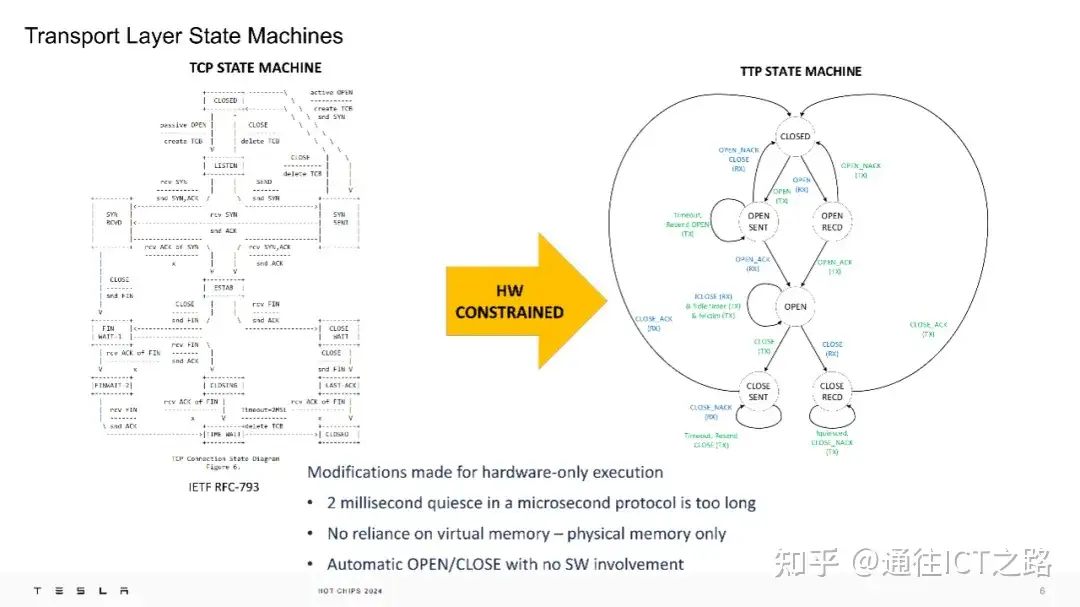
下面的胶片,特斯拉展示了 TCP 状态机与 TTP 状态机的对比:TTPoE 的传输层状态机针对硬件执行进行了优化,例如,将原本 2ms 的静默时间缩短,以适应微秒级的协议需求,并避免了对虚拟内存的依赖,仅使用物理内存。
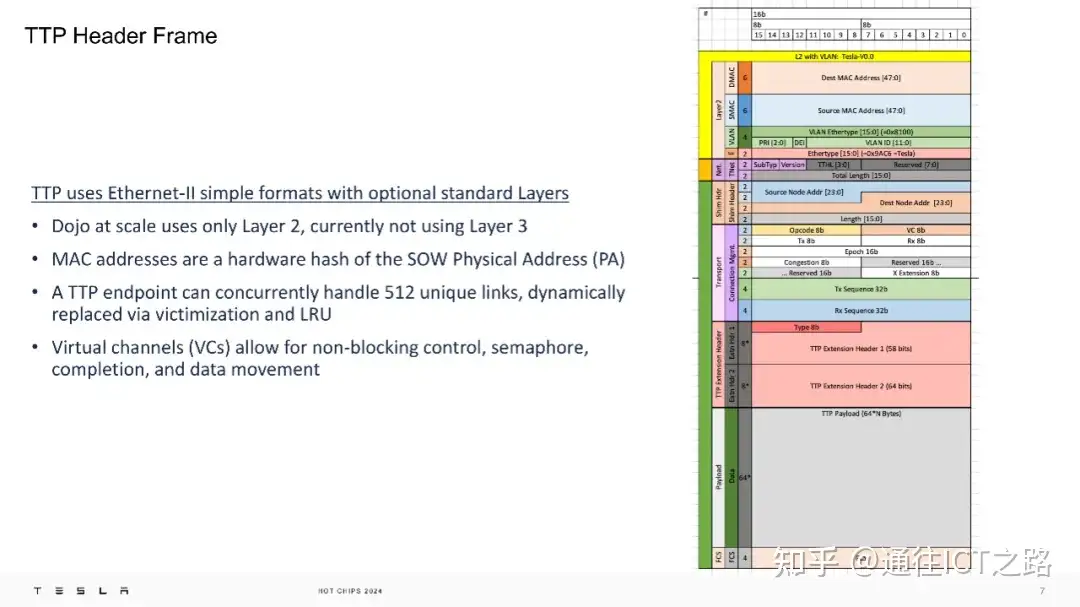
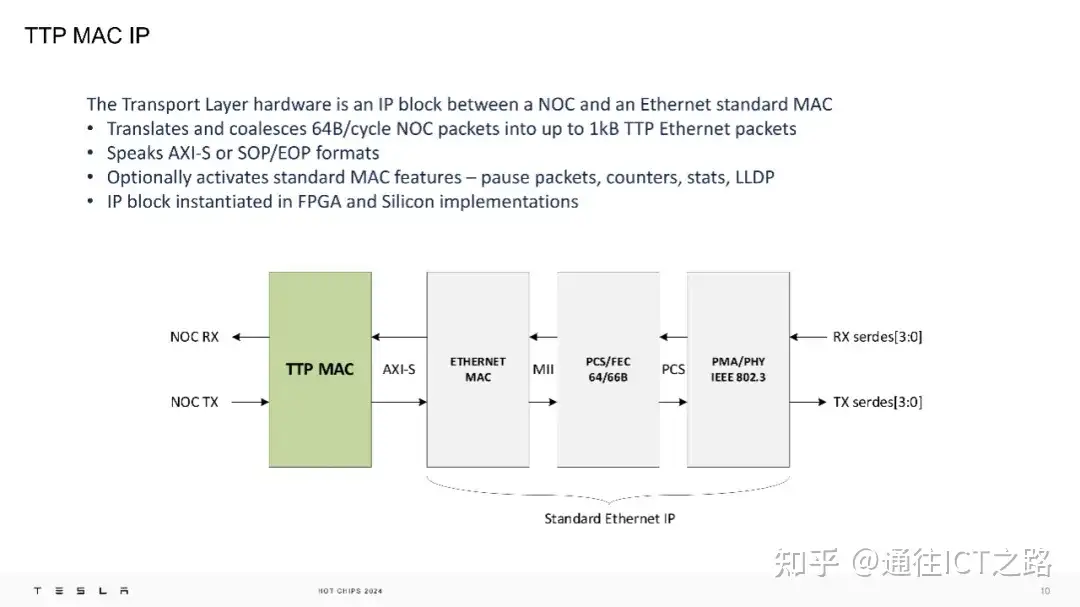
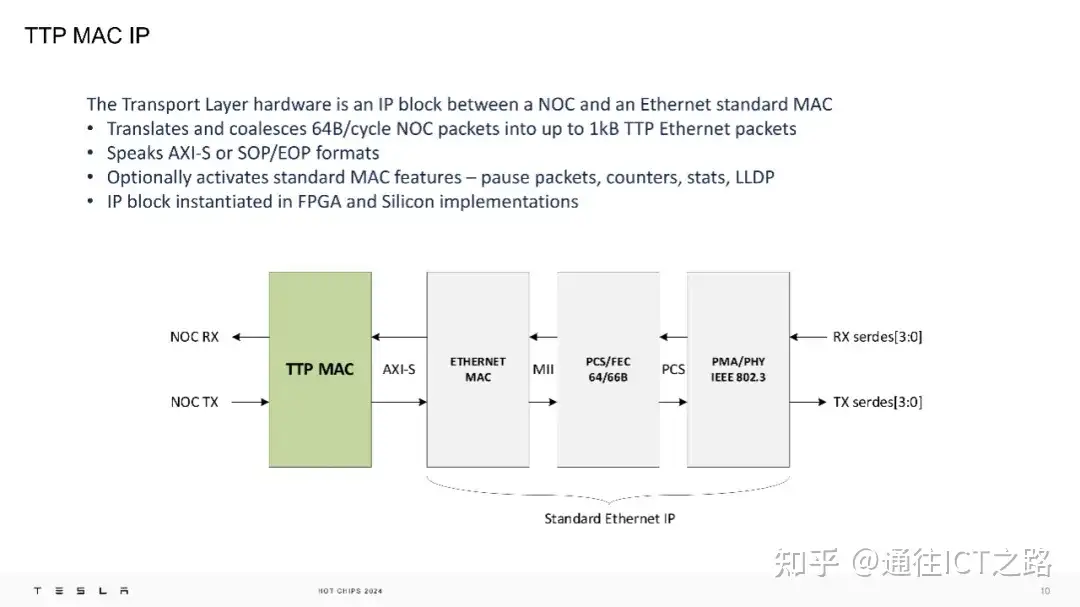
在物理层面,TTPoE 使用 Ethernet-II 简单格式,仅在第二层操作,不涉及第三层网络。Dojo 超级计算机的每个传输层硬件都是一个 IP 模块,位于网络芯片(NOC)和标准的以太网 MAC 之间。
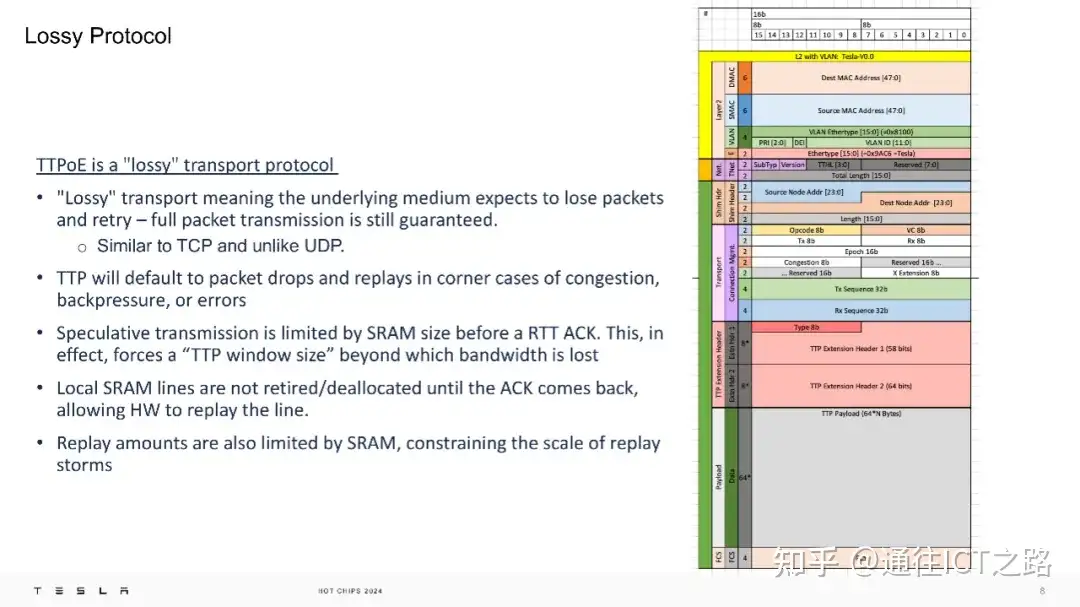
TTPoE 协议具有“有损”特性,意味着它预期在网络拥塞、背压或错误的情况下丢包并重传,但仍然保证完整的数据包传输。这种设计类似于 TCP 而不是 UDP,它通过限制在收到确认(ACK)前的推测性传输量,有效管理了带宽使用。
另外,TTPoE 的拥塞管理是分布式的,由本地链路的发送通道处理,而不是由中央网络或交换机控制。这种设计避免了依赖优先级流控制(PFC)和 Nagel 算法等无损网络机制,从而降低了网络的复杂性和脆弱性。
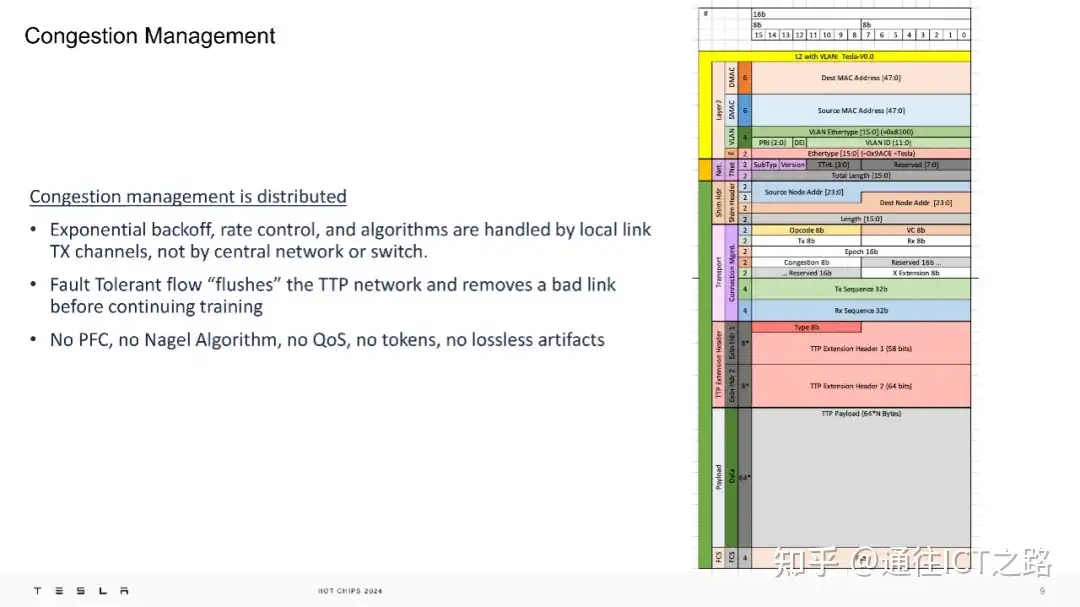
特斯拉表示 TT P支持服务质量(QoS),但目前该功能已被关闭。
特斯拉将 TTP 的 IP 模块集成到了 FPGA 和硅芯片中,其设计目的是在线上快速传输数据包。
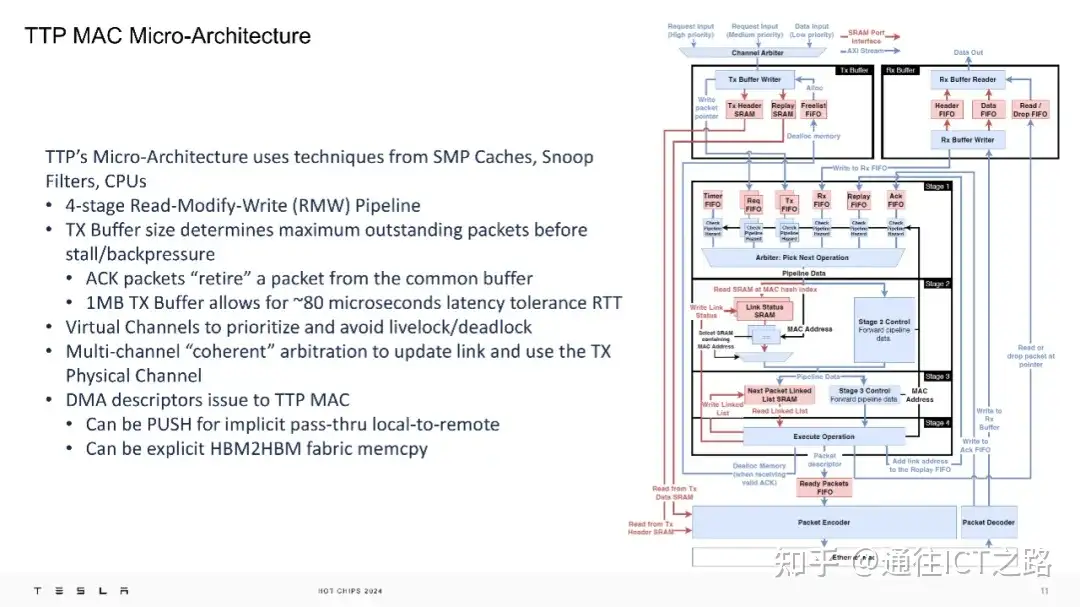
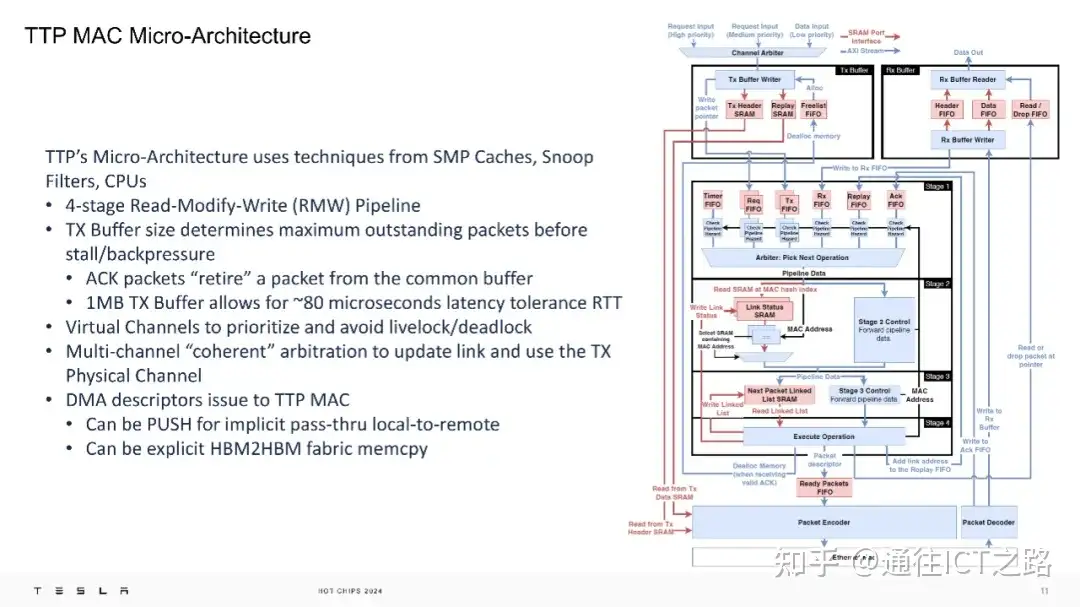
在微架构层面,TTP 的微架构设计独特,看起来非常像一个 L3 缓存,采用了类似于 SMP 缓存、窥探过滤器和 CPU 的技术,拥有4 阶段的读写修改(RMW)。1MB 的发送缓冲区允许大约 80 微秒的往返延迟容忍度,虚拟通道用于优先处理和避免活锁/死锁。1MB 的发送缓冲区在当前这一代产品中被提及,但有可能在新一代产品中有所变化。
特斯拉展示了其 100Gbps 的 “Mojo” 网卡,这是一种“哑”网卡,具备1 00Gbps 的以太网速度、PCI-e Gen3 x16 接口、8GB DDR4 内存,并且功耗低于 20W。它还集成了 Dojo DMA 引擎,支持 512 个独特的双向 LRU 活动链接。

在大会上,特斯拉回顾了 2022 年关于 D1 芯片的介绍。
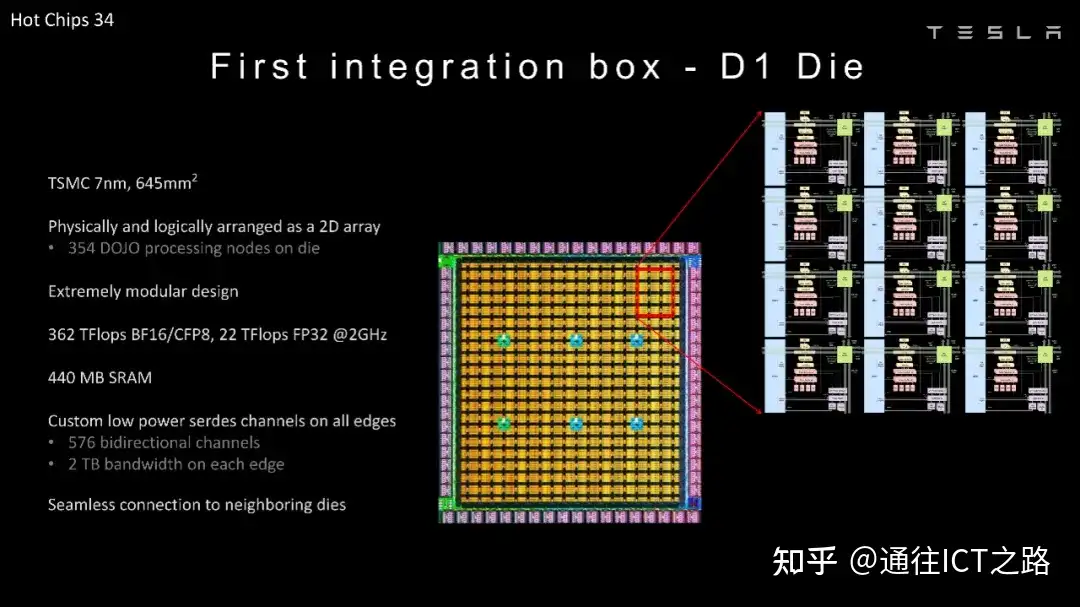
下图展示的是 5×5 阵列的 D1 芯片封装。

Dojo 接口处理器则包含 32GB 的高带宽内存,提供 800GB/s 的总内存带宽和 900GB/s 的 TTP 接口。900GB/s 的 TTP 接口是内部的,TTPoE 则被封装在以太网帧中。

接着,特斯拉展示了 Dojo 的连接方式。Tesla 100G NIC 转 V1 Dojo 接口卡转 Dojo。

从组装好的 D1 芯片阵列开始,通过 SerDes 电缆连接到接口卡。

这些将转到 Interface Cards。

然后,这些接口卡随后连接到低成本的 100G NIC。

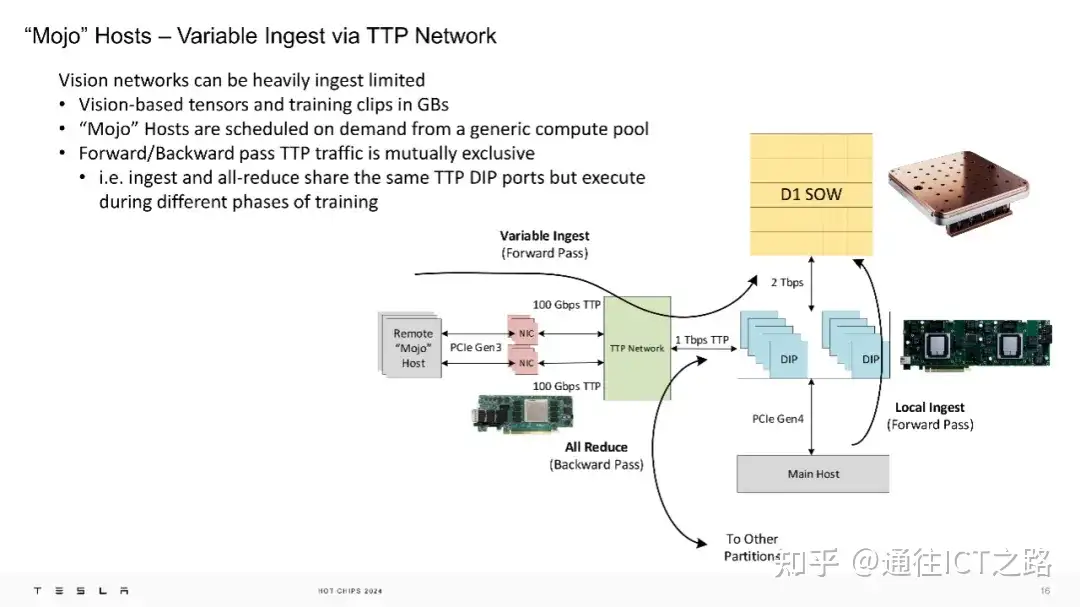
在特斯拉的TTP网络中,”Mojo” 主机通过可变的数据摄入方式运行。视觉网络可能会受到数据摄入的限制,因为基于视觉的张量和训练片段可能以 GB 为单位。”Mojo” 主机根据需求从通用计算池中调度。前向/反向传递的 TTP 流量是相互独立的,即数据摄入和全约简操作共享相同的 TTP DIP 端口,但在训练的不同阶段执行。
下面的胶片展示的是位于纽约的 Mojo Dojo 计算大厅。我们可以看到2U 计算节点没有任何前置 2.5 英寸存储。

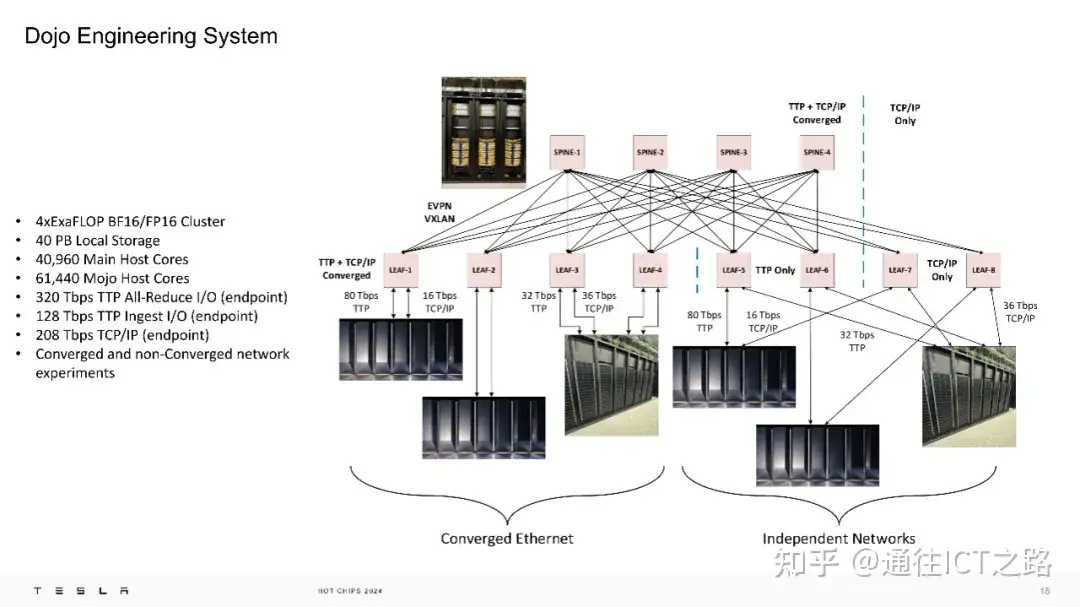
这是一个 4 ExaFLOP 的工程系统,配备了 40PB 的本地存储,以及大量的带宽和计算能力。拥有一个 4EF(BF16/FP16) 的工程系统也相当惊人。
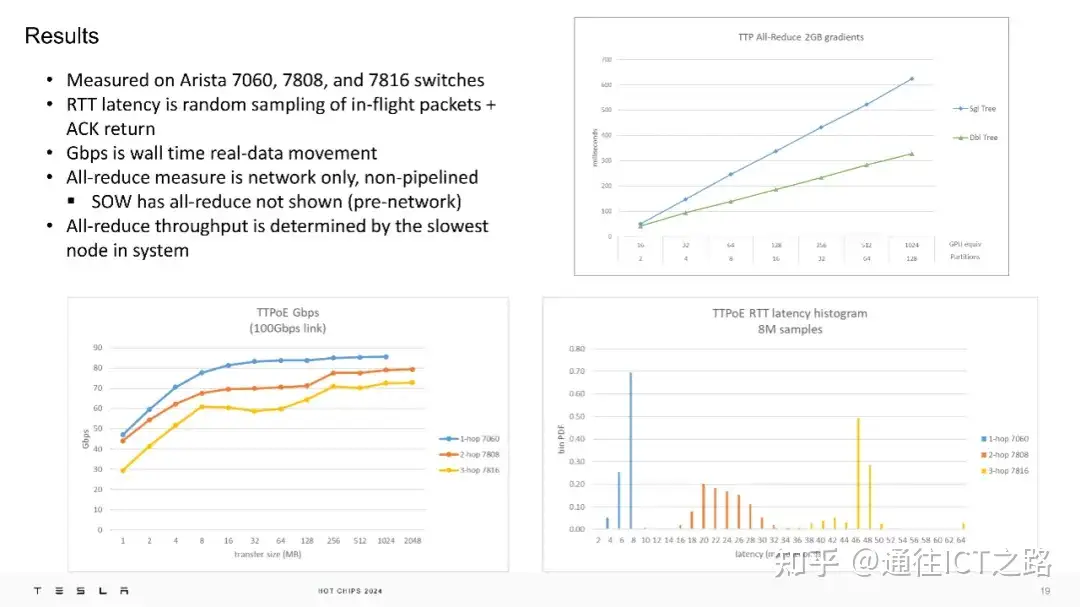
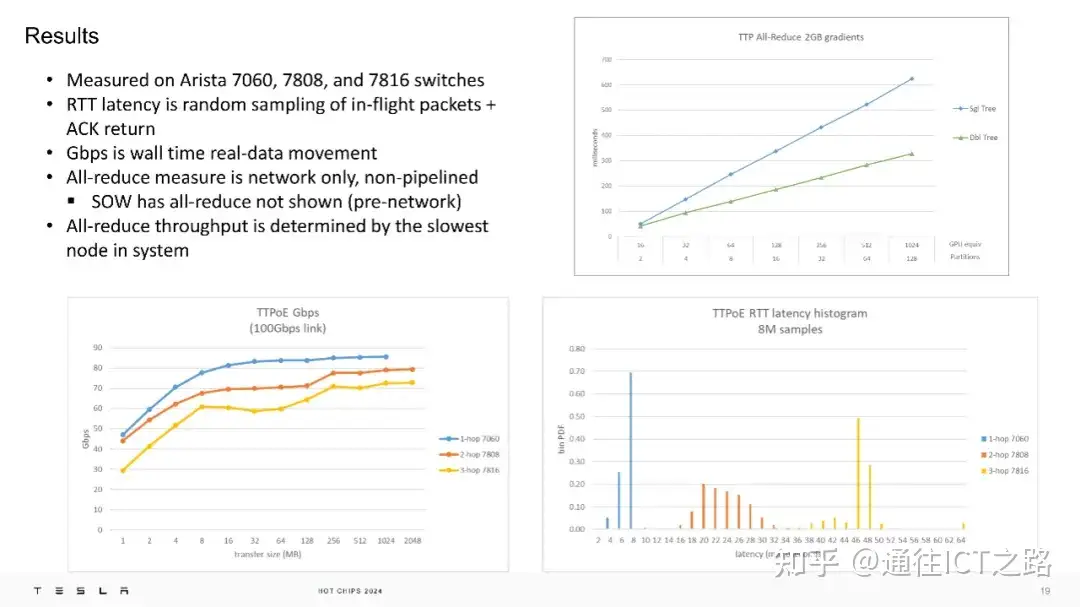
在实际测试中,TTPoE 在 Arista 的 7060、7808 和 7816 交换机上进行了测量,结果显示其具有较低的往返延迟和高吞吐量。
特斯拉加入了超以太网联盟(UEC),并公开提供 TTPoE 协议,以支持更广泛的网络运营商。

特斯拉感谢:TTPoE 的原始发明者、网络部署团队、硅设计团队、系统和基础设施团队、软件和驱动团队、Linux 补丁团队、SDN 团队、DevOps 团队、QA 团队、DC 技术团队、供应链团队以及所有 TTP/Mojo 实习生的贡献。

最后,在网络性能方面,特斯拉认为应当减少对合成延迟测量的过度关注,因为这种测量往往不能全面反映实际网络的性能。更有意义的差异点包括有损与无损网络的对比;集中式与分布式处理网络拥塞的方法以及专有技术与开源技术的不同。
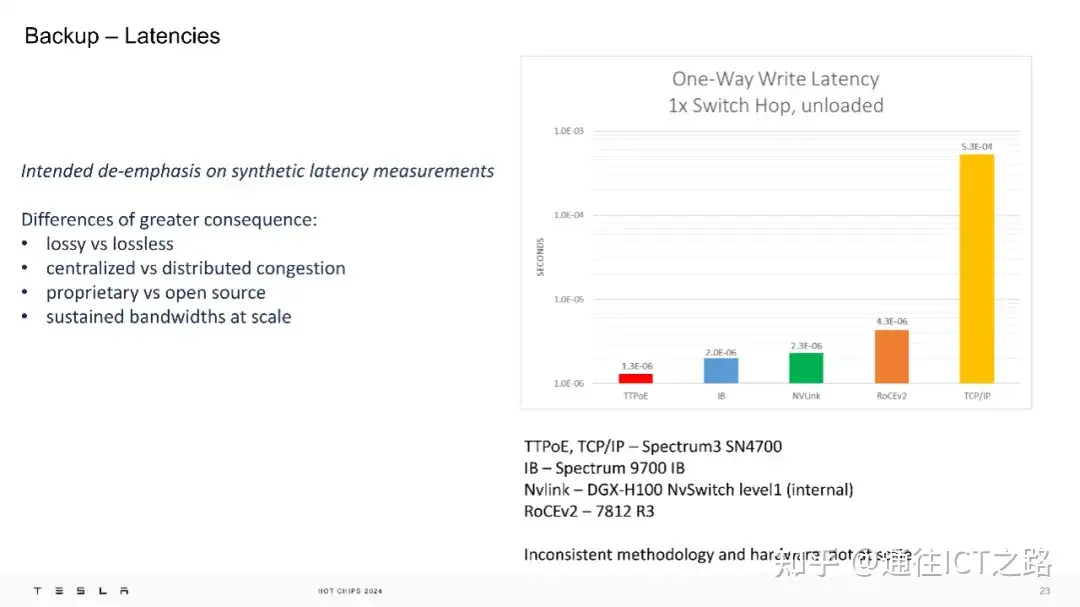
进一步地,展示了在空载情况下,1 次交换跳转的单向写入延迟的测量结果,提供了几种不同技术的延迟数据。具体来说,TTPoE 的延迟为1.0E-05s,InfiniBand (IB)为2.0E-06s,NVLink为2.3E-06s,RoCEv2为4.3E-06s,而TCP/IP的延迟最高,为5.3E-04s。
特斯拉的结论是,他们的系统性能已经达到了微秒级。
迎加我微信:备注“数通” ,加入数通专业群!

有采用传统的 TCP 协议,而是为其 Dojo 超级计算机开发了一种新的有损以太网传输协议:Tesla Transport Protocol over Ethernet (TTPoE) 。
此协议专为 AI 超级计算机设计,以实现 Exa 级网络架构的数据传输。
与传统的 TCP/IP 协议相比,TTPoE 在硬件层面执行,以解决 AI 互连的延迟问题,它通过简化的软件和硬件设计,实现了更低的延迟和更高的带宽。

原因是:特斯拉认为 TCP/IP 协议速度过慢,而使用 PFC(优先级流控制)的 RDMA (远程直接内存访问)虽然能实现无损网络,但会对网络性能造成影响。

在下面的介绍中,指出 TTPoE 是一个在硬件层面执行的点对点传输层协议,其优势在于特斯拉无需使用特殊的交换机,因为它主要利用的是第二层(数据链路层)的传输。

也就是说,在 Dojo 的 OSI 模型中,特斯拉用 TTPoE 取代了传统的传输层。
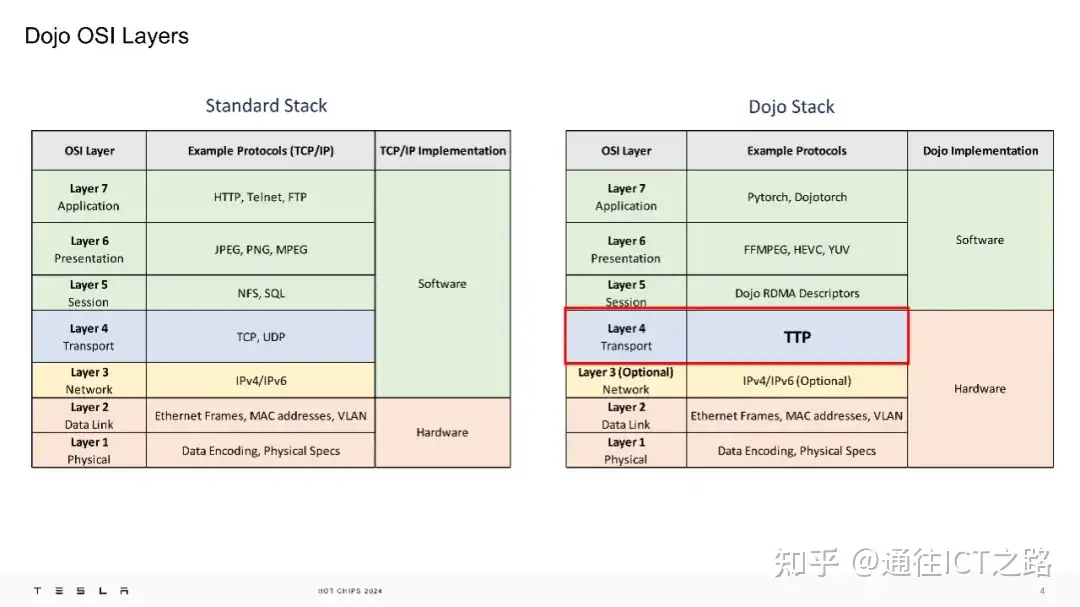
通过 TTP 链路,我们可以看到 TTP 协议的转换示例。
下面的胶片,特斯拉展示了 TCP 状态机与 TTP 状态机的对比:TTPoE 的传输层状态机针对硬件执行进行了优化,例如,将原本 2ms 的静默时间缩短,以适应微秒级的协议需求,并避免了对虚拟内存的依赖,仅使用物理内存。
在物理层面,TTPoE 使用 Ethernet-II 简单格式,仅在第二层操作,不涉及第三层网络。Dojo 超级计算机的每个传输层硬件都是一个 IP 模块,位于网络芯片(NOC)和标准的以太网 MAC 之间。
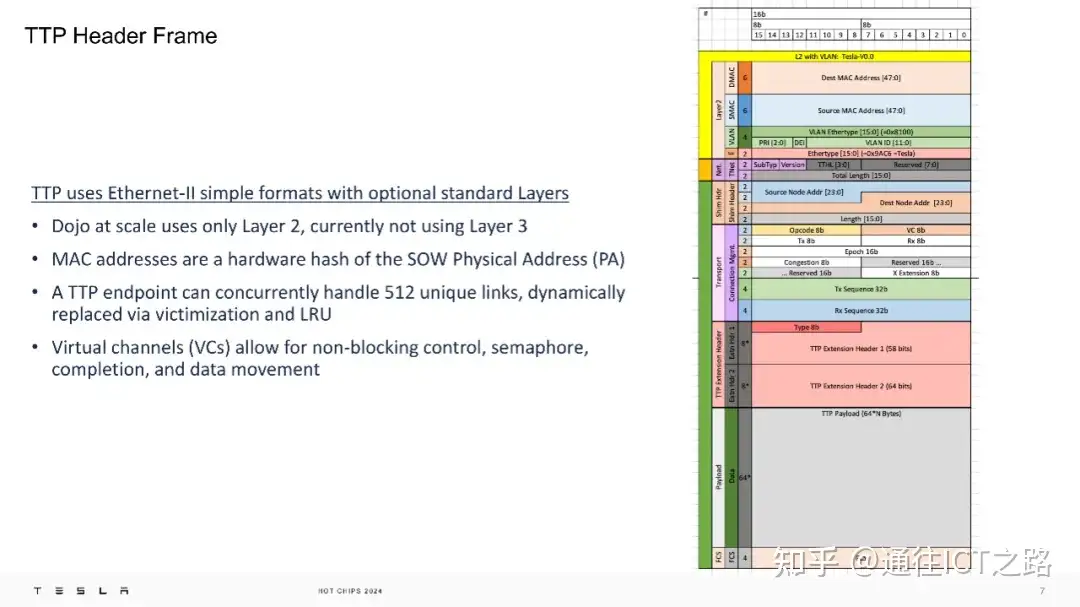
TTPoE 协议具有“有损”特性,意味着它预期在网络拥塞、背压或错误的情况下丢包并重传,但仍然保证完整的数据包传输。这种设计类似于 TCP 而不是 UDP,它通过限制在收到确认(ACK)前的推测性传输量,有效管理了带宽使用。
另外,TTPoE 的拥塞管理是分布式的,由本地链路的发送通道处理,而不是由中央网络或交换机控制。这种设计避免了依赖优先级流控制(PFC)和 Nagel 算法等无损网络机制,从而降低了网络的复杂性和脆弱性。
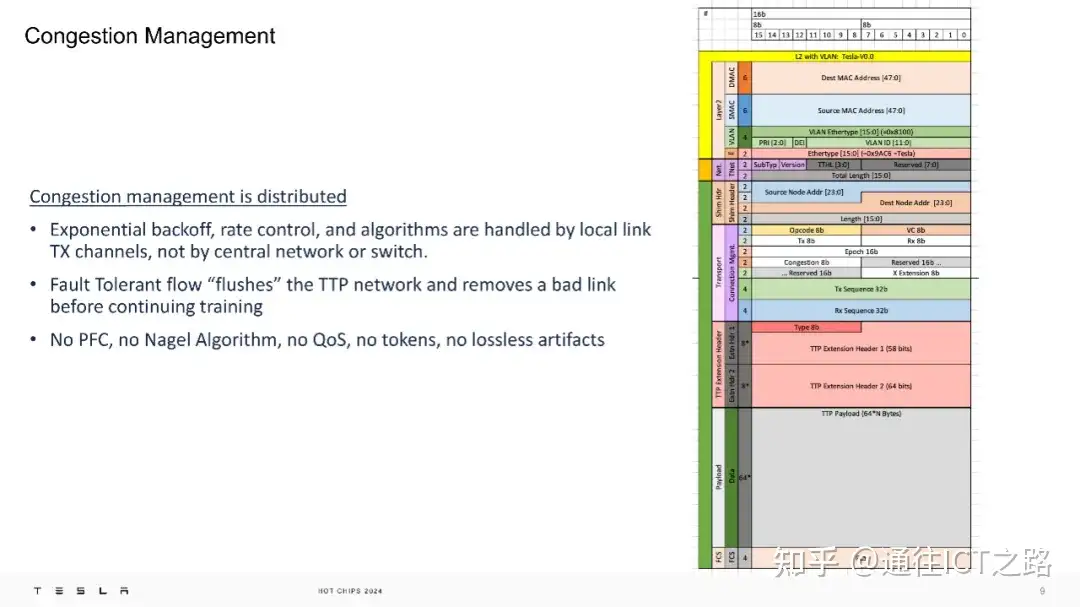
特斯拉表示 TT P支持服务质量(QoS),但目前该功能已被关闭。
特斯拉将 TTP 的 IP 模块集成到了 FPGA 和硅芯片中,其设计目的是在线上快速传输数据包。
在微架构层面,TTP 的微架构设计独特,看起来非常像一个 L3 缓存,采用了类似于 SMP 缓存、窥探过滤器和 CPU 的技术,拥有4 阶段的读写修改(RMW)。1MB 的发送缓冲区允许大约 80 微秒的往返延迟容忍度,虚拟通道用于优先处理和避免活锁/死锁。1MB 的发送缓冲区在当前这一代产品中被提及,但有可能在新一代产品中有所变化。
特斯拉展示了其 100Gbps 的 “Mojo” 网卡,这是一种“哑”网卡,具备1 00Gbps 的以太网速度、PCI-e Gen3 x16 接口、8GB DDR4 内存,并且功耗低于 20W。它还集成了 Dojo DMA 引擎,支持 512 个独特的双向 LRU 活动链接。

在大会上,特斯拉回顾了 2022 年关于 D1 芯片的介绍。

下图展示的是 5×5 阵列的 D1 芯片封装。

Dojo 接口处理器则包含 32GB 的高带宽内存,提供 800GB/s 的总内存带宽和 900GB/s 的 TTP 接口。900GB/s 的 TTP 接口是内部的,TTPoE 则被封装在以太网帧中。

接着,特斯拉展示了 Dojo 的连接方式。Tesla 100G NIC 转 V1 Dojo 接口卡转 Dojo。

从组装好的 D1 芯片阵列开始,通过 SerDes 电缆连接到接口卡。

这些将转到 Interface Cards。

然后,这些接口卡随后连接到低成本的 100G NIC。

在特斯拉的TTP网络中,”Mojo” 主机通过可变的数据摄入方式运行。视觉网络可能会受到数据摄入的限制,因为基于视觉的张量和训练片段可能以 GB 为单位。”Mojo” 主机根据需求从通用计算池中调度。前向/反向传递的 TTP 流量是相互独立的,即数据摄入和全约简操作共享相同的 TTP DIP 端口,但在训练的不同阶段执行。

下面的胶片展示的是位于纽约的 Mojo Dojo 计算大厅。我们可以看到2U 计算节点没有任何前置 2.5 英寸存储。
这是一个 4 ExaFLOP 的工程系统,配备了 40PB 的本地存储,以及大量的带宽和计算能力。拥有一个 4EF(BF16/FP16) 的工程系统也相当惊人。
在实际测试中,TTPoE 在 Arista 的 7060、7808 和 7816 交换机上进行了测量,结果显示其具有较低的往返延迟和高吞吐量。
特斯拉加入了超以太网联盟(UEC),并公开提供 TTPoE 协议,以支持更广泛的网络运营商。
特斯拉感谢:TTPoE 的原始发明者、网络部署团队、硅设计团队、系统和基础设施团队、软件和驱动团队、Linux 补丁团队、SDN 团队、DevOps 团队、QA 团队、DC 技术团队、供应链团队以及所有 TTP/Mojo 实习生的贡献。

最后,在网络性能方面,特斯拉认为应当减少对合成延迟测量的过度关注,因为这种测量往往不能全面反映实际网络的性能。更有意义的差异点包括有损与无损网络的对比;集中式与分布式处理网络拥塞的方法以及专有技术与开源技术的不同。
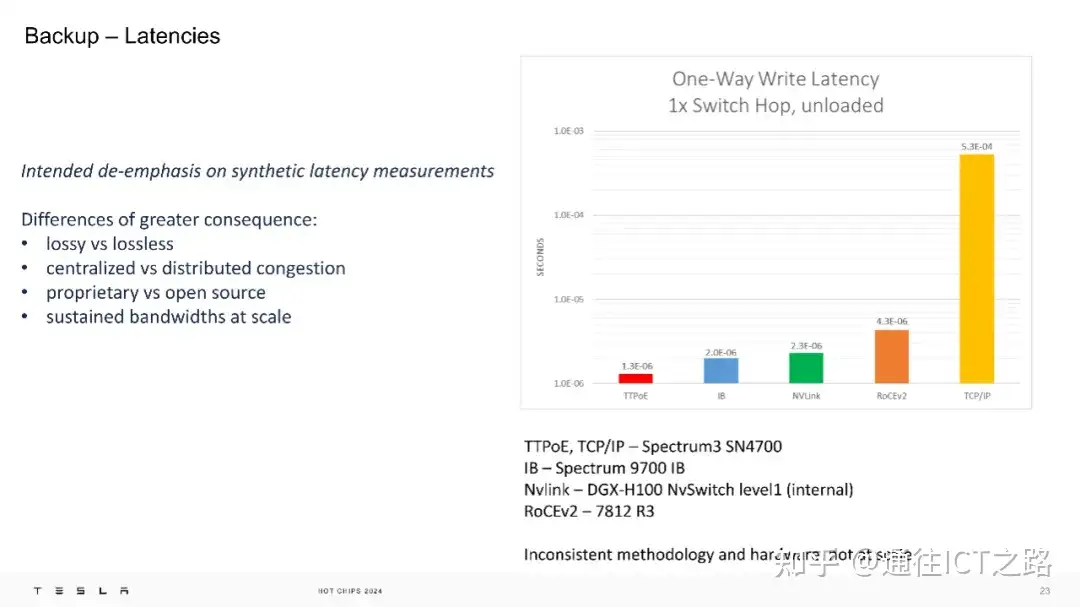
进一步地,展示了在空载情况下,1 次交换跳转的单向写入延迟的测量结果,提供了几种不同技术的延迟数据。具体来说,TTPoE 的延迟为1.0E-05s,InfiniBand (IB)为2.0E-06s,NVLink为2.3E-06s,RoCEv2为4.3E-06s,而TCP/IP的延迟最高,为5.3E-04s。
特斯拉的结论是,他们的系统性能已经达到了微秒级。
迎加我微信:备注“数通” ,加入数通专业群!
