
什么是ASIC芯片?
ASIC,全称为 Application Specific Integrated Circuit,中文名为专用集成电路芯片,顾名思义,是一种为了专门目的或者算法而设计的芯片。ASIC 芯片的架构并不固定,既有较为简单的网卡芯片,用于控制网络流量,满足防火墙需求等等,也有类似谷歌 TPU,昇腾 910B 一类的顶尖 AI 芯片。ASIC 并不代表简单,而是代表面向的需求,只要是为了某一类算法,或者是某一类用户需求而去专门设计的芯片,都可以称之为 ASIC。当下,ASIC 芯片的主要根据运算类型分为了 TPU、DPU 和 NPU 芯片,分别对应了不同的基础计算功能。TPU 即为谷歌发明的 AI 处理器,主要支持张量计算,DPU 则是用于数据中心内部的加速计算,NPU 则是对应了上一轮 AI 热潮中的 CNN 神经卷积算法,后来被大量 SoC 进了边缘设备的处理芯片中。从芯片大类来看,目前人类的芯片可以被分为 CPU、GPU、FPGA、ASIC 四种大类:
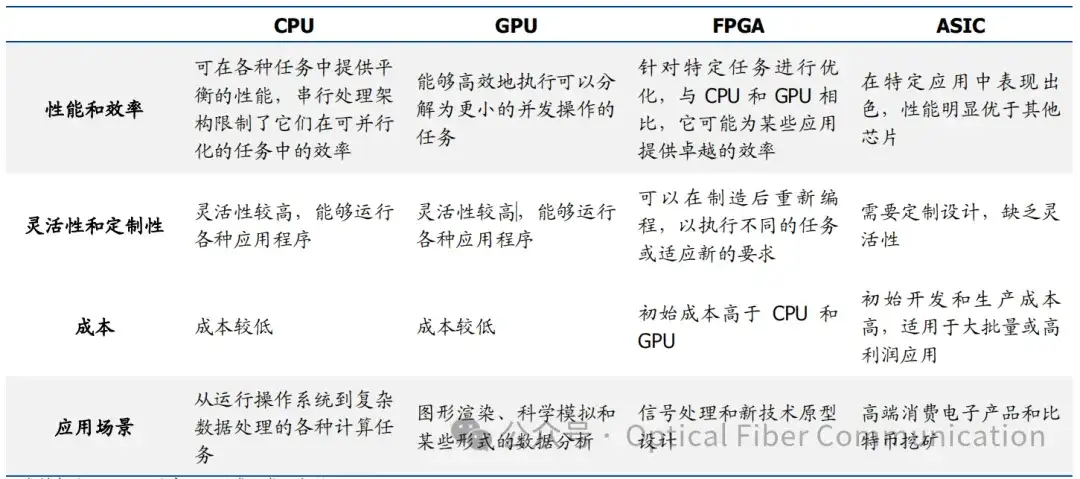
其中 CPU 是人类芯片之母,拥有最强的通用性,适合复杂的指令与任务,GPU 则是人类历史上的第一大类“ASIC”芯片,通过大量部署并行计算核,实现了对于异构计算需求的优化。FPGA 芯片则更加强调可编程性,可以通过编程重新配置芯片内部的逻辑门和存储器,但是运算性能较低。ASIC 则完全为某类功能或者算法专门设计,通用性较低的同时,拥有对某一类算法最好的性能。
芯片大势,通久必专,专久必通
从最早的 CPU 独霸天下,到并行计算时代 GPU 的崛起,挖矿时代专用 ASIC 的大放异彩,我们不难发现,新芯片的出现,往往是因为某一类需求的爆发,从而使得过往通用型芯片中的特定功能被分割出来,形成了新的芯片类目。通用芯片发现需求、探索需求,专用芯片满足需求,这就是半导体行业面对人类需求时的解决之道,归根结底,需求决定一切,芯片的架构能否满足契合客户的需求,是决定一个芯片公司能否成功的重要因素。大模型时代,风来的如此之快,2023 年春节之前,业界还在努力优化复杂的 CNN 算法,追求模型的小而美,之后随着 GPT 和 OPENAI 的横空出世,将业界热点算法迅速从 CNN转变为 Transformer,底层运算也变为矩阵乘法。同时由于大模型“大力出奇迹”的特性,对于算力的需求极速释放,2023 年来看,唯一能够满足用户这一新需求的依然只有较为通用的英伟达芯片,因此,也在这一年多内造就了英伟达 2w 亿美金的传奇市值。但天下芯片,通久必专,专久必通,当矩阵乘法这一固定运算占据了大部分的大模型运算需求时,通用芯片中的小核心,甚至是向量计算核心,逐渐成为了功耗、成本和延迟的负担,客户终究不会因为单一的矩阵乘法需求,而为通用性去额外买单。因此,从海外大厂到无数业界大佬的创业公司,纷纷加入了“矩阵乘法”ASIC,又或者是大模型 ASIC的创业浪潮中,在下文中,我们将列举两个较为有代表性的 ASIC 芯片,去看看业界的设计思路与演化方向。
大模型 ASIC 的发展路线
从历史来看,我们通过剖析 GPU 的结构和其与 CPU 的区别,不难发现,GPU 也是某种意义上的 ASIC,过去的数据处理任务,通常是单条复杂指令或逻辑运算,但随着图像处理需求的出现,计算过程中往往开始包含大量并行的简单计算,而 CPU 由于核心数量有限,虽然单核能够处理较为复杂的指令,但面对大量简单计算时,运算时间长的缺点逐渐暴露。所以正如前文所说,CPU 作为人类最通用的芯片,带领人类进入并探索了图像时代,紧接着,面对海量释放的 AI 需求,GPU 作为“图像 ASIC”横空出世,满足了海量的图像处理需求。
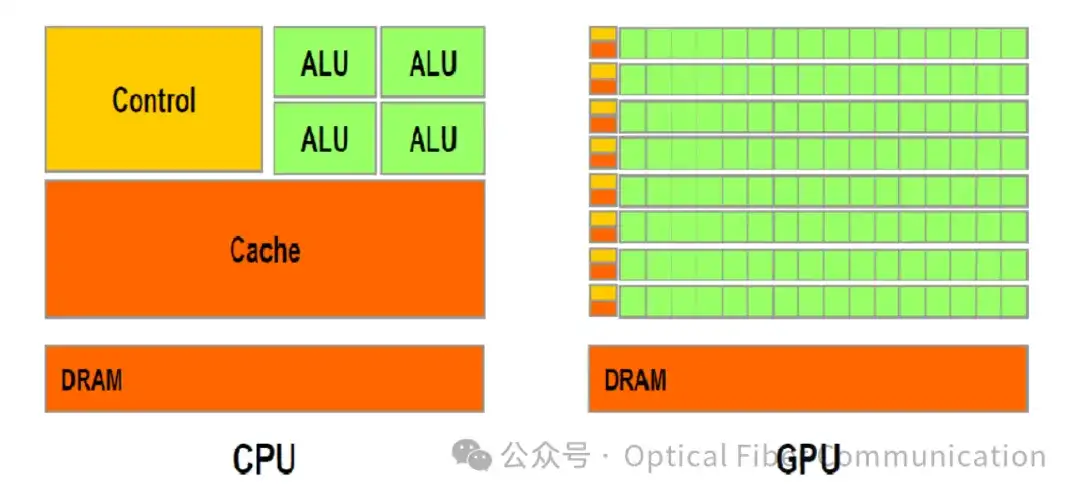
进一步探究 GPU 的发展历程,我们会发现芯片趋势的第二部分,如果说 CPU 到 GPU 是我们提到的“通久必专”,那么 GPU 本身的发展历史则是“专久必通”的最好诠释。在并行计算早期,算法大多数是由简单的加减乘除构成,因此通过在 GPU 芯片内部署大量的小核来并行计算这些简单算法。但后来,随着并行计算,或者说图像处理需求慢慢衍生出图像识别、光线追踪、机器视觉等等新功能和与之对应的以“卷积计算”为代表的新算法,GPU 本身也从专用芯片,变成了面向并行计算模式或者海量图像需求的“通用芯片”。
主要技术趋势总结
往后来看,ASIC 的发展也将聚焦于两个方向:
第一个方向为“Wafer-Scaling”,以 SamAltman 投资的 cerebras 为例,即扩大单个芯片面积,实现在单个芯片内装在更多的 MXU,也即是矩阵计算核心。这样单次运算能够处理的数据量就更大,是最简单和直接的升级路线。第二个方向即为“近存计算”,Groq 给我们具体展示了这一路线,MXU 将数据运算后直接转移给相邻的 sRAM,由于传输距离短,叠加 sRAM 天生的高带宽,从而实现了绕过 HBM 的流水线式加工,我们认为这种通过近计算单元的高速存储,来实现计算单元之间高速沟通的模式,将会是大模型 ASIC 发展的另一主要方向。