人工智能数据中心对可扩展互连的迫切需求,正推动基于微机电系统(MEMS)的光电路交换技术(OCS)迎来关键突破。
OCS 光电路交换是怎么工作的呢?
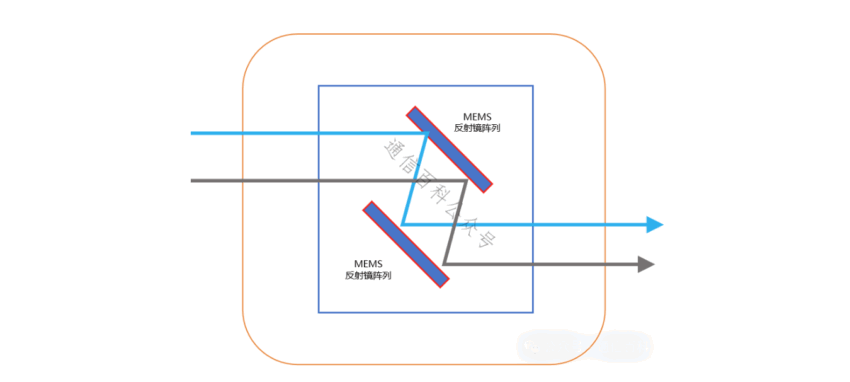
在OCS系统里,光信号从一个端口进来,碰到一个布满微型反射镜的“矩阵”。这些镜子特别灵活,能快速调整角度,把进来的光信号精准地“弹”到指定的输出端口上。
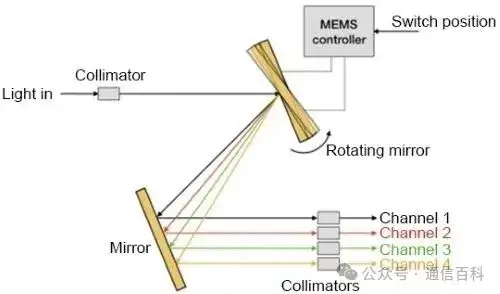
这样就建立了一条点对点的光路通道。最大的好处是,数据全程都在光路上跑,完全不用转成电信号。 这就直接打通了端到端的连接,把传输延迟压到了最低。
以Lumentum的R300交换机为例,对比传统以太网交换机性能:

为什么AI数据中心这么需要OCS呢?主要是传统架构撑不住了。
像常用的Clos或Fat-Tree架构,靠的是好几层电交换机(通常2-3层)把GPU或TPU这些计算单元连起来。问题在于,规模越大,耗电和成本就涨得越吓人,几乎是成倍往上翻。OCS提供了一个新思路:用它直接替换掉最顶层、最核心也最耗电的那部分“主干”电交换机。 这样一来,整个互连架构就简化成了单层的光连接。
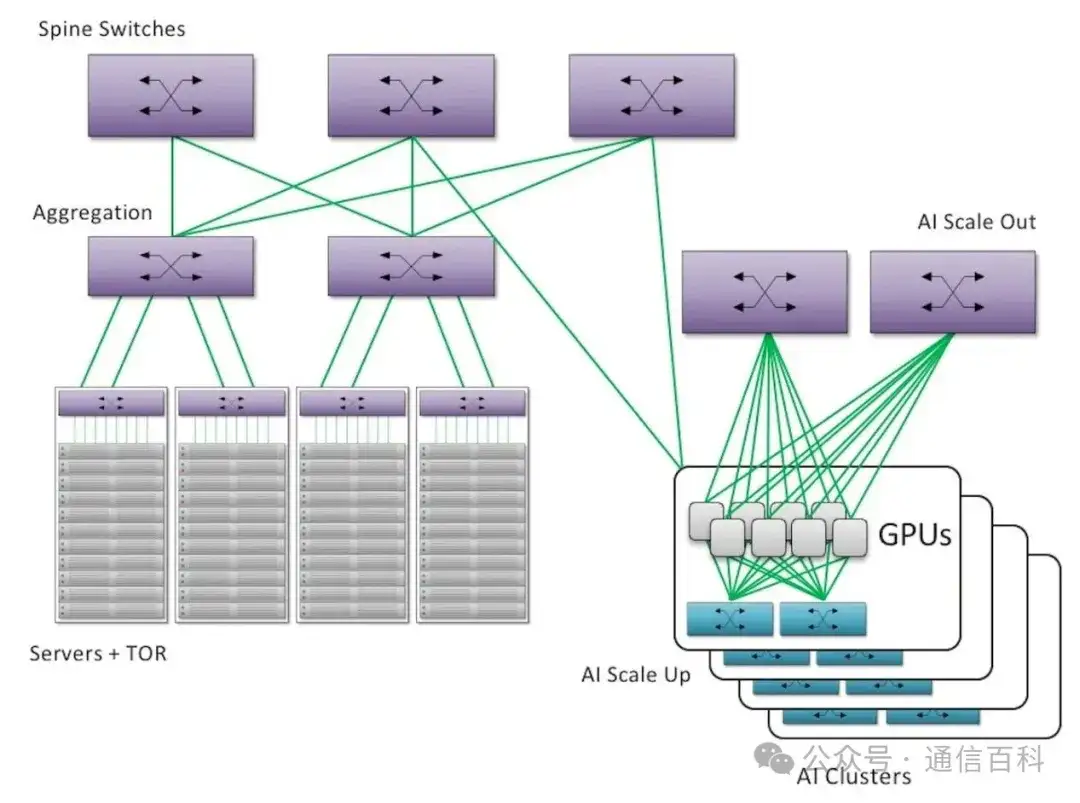
Clos 架构中排列的电气开关层
谷歌的实际应用已经看到了明显好处:他们的TPU集群互连功耗直接降了40%!而且,光路可以灵活调整,万一哪个机架出问题,数据能自动绕开走别的光路,可靠性也提高了。
还有个面向未来的大优势:OCS是“协议透明”的。 简单说,它不挑食,现在400G、800G的链路能用,未来升级到1.6T,也不用换硬件本身,直接兼容。
不过,想实现这个突破,还有很多问题需要解决!
像Lumentum的R300交换机,里面有几万面小镜子,每一个都得精确控制到微米级别,对准不能差。光信号每穿过一个输入或输出端口都会有损耗(一开始大概1.5dB,标称3dB),一来一回就是6dB的损耗,这对信号能传多远影响很大。另外,镜子反射时产生的杂散光(背向反射)必须压得非常非常低(大概60dB的量级),才能不干扰其他信号,这对镜子的表面精度要求简直苛刻。
同时,为了在有限空间里塞下更多连接(提升端口密度),大家想到了用双向光模块(一个端口当两个用)。这招确实让端口数翻倍了,但也得用定制的、非标准的光收发器。更头疼的是,控制整个系统的软件复杂度一下子激增,因为得时刻盯着,防止两条方向相反的光在同一路径上“撞车”(冲突检测)。
那些小镜子的活动关节(铰链)得超级耐用,要能承受住天文数字般的开关次数(比如10¹⁵次,相当于连续工作20年不停)。温度变化会让镜子位置漂移,导致光路不准,所以还得有实时监测和补偿的闭环系统。目前,能把MEMS做到电信级高可靠性的厂商很少,像有些厂商在波长选择开关上有十几万台设备的部署经验。但要把同样的可靠性和精度搬到数据中心用的OCS产品上,并且能大规模量产保证良率,这还是个挑战。
接下来,光电路交换技术会怎么发展呢?
首先,混合架构成为必然选择,指望OCS包打天下不现实。比较可行的方案是让它处理AI训练里那种持续不断的、大块的数据流(比如AllReduce通信),而把零碎的小数据包交给传统的以太网电交换机去处理。这就要求背后的控制系统非常智能,能动态感知流量类型并灵活调度。
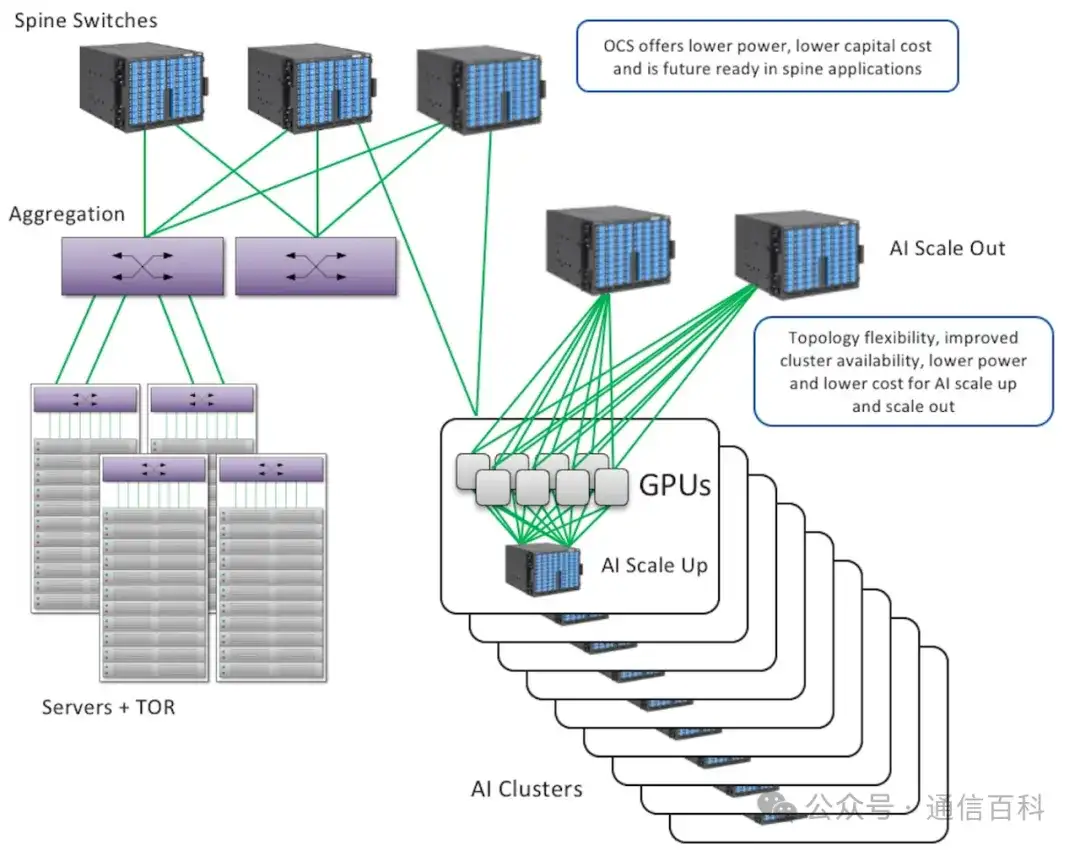
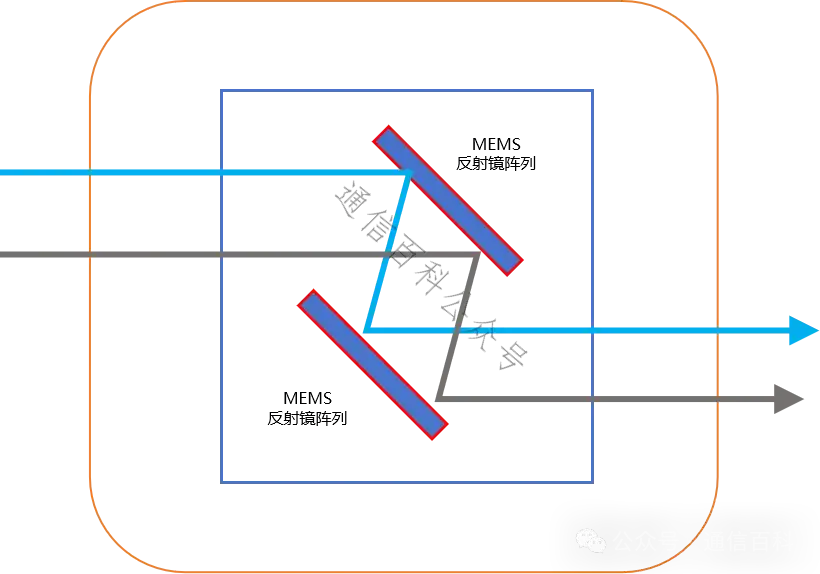
如数据中心中的光电路开关(蓝框)
现在一个端口通常只处理一路光。未来技术会实现在一个端口内,对多个不同波长的光信号分别进行调度(就像把一条大路分成多条车道),这样频谱利用效率会大幅提升。
最后, 把OCS和“共封装光学”(CPO)技术结合起来,能省掉可插拔光模块,进一步减少信号损耗。另外,利用AI去分析那些控制镜子偏转的数据,可以提前预测可能出现的故障,让整个系统运行得更稳当。
感谢阅读!